1. Population Balances for Polymer Systems#
Real polymerization systems can involve tens or even hundreds of distinct reactions. However, from a formal perspective, most reactions can be viewed as particular cases of a handful of fundamental reaction steps. In this notebook, we will focus on the four most important base steps through which polymer chains grow and/or break: propagation, depropagation, combination, and scission.
from typing import Callable
import matplotlib.pyplot as plt
import numpy as np
from scipy.integrate import solve_ivp
1.1. Propagation#
The chemical equation for the propagation step is given by:
Here, \(k\) is the propagation rate constant, and we assume it is independent of chain length. The corresponding population balance equation can be written as:
where \([P_i]\) represents the concentration of a polymer chain with \(i\) monomer units, and \([M]\) is the monomer concentration.
Next, the derivatives of the first three moments, \(\lambda_m=\sum_{i=1}^{\infty} i^m P_i\), are:
These equations indicate:
The number of chains is conserved (since \(\dot{\lambda}_0=0\)).
The total number of monomer units incorporated into chains increases at the same rate that the monomer concentration decreases (i.e., \(\dot{\lambda}_1 = -\frac{\textrm{d}[M]}{\textrm{d}t}\)).
1.1.1. Numerical Solution#
In this section, we will solve the derived equations numerically and generate plots to visualize the evolution of chain length, monomer concentration, and other relevant quantities over time.
First of all, let’s define a function to evaluate \(\textrm{d}[P_i]/\textrm{d}t\) for the propagation step.
def propagation(P: np.ndarray, M: float, k: float) -> np.ndarray:
"""P(i) + M --> P(i+1) , k
d[P(i)]/dt = k*[M]*([P(i-1)] - [P(i)])
"""
Pdot = k*M*(np.roll(P, 1) - P)
Pdot[0] = -k*M*P[0]
return Pdot
Next, we’ll define two helper functions. The first will compute the \(m\)-th moment of a distribution.
def moment(P: np.ndarray, m: int):
"""m-th moment of `P`.
Parameters
----------
P : np.ndarray
Distribution.
m : int
Order of moment.
Returns
-------
float | np.ndarray
Moment of distribution `P`.
"""
s = np.arange(0, P.shape[0])
return np.dot(s**m, P)
The second helper function will integrate the population balances and plot both the full distribution and its leading moments.
def solve_pbe(Pdot: Callable,
P0: np.ndarray,
tend: float,
make_plots: bool = True
) -> tuple[np.ndarray, np.ndarray]:
"""Solve PBE and plot results.
Parameters
----------
Pdot : Callable
Derivative of distribution.
P0 : np.ndarray
Initial distribution.
tend : float
End time.
make_plots : bool
Whether to make plots.
Returns
-------
tuple[np.ndarray, np.ndarray]
Time and distribution.
"""
# Solve ODE
teval = np.linspace(0.0, tend, num=100+1)
solution = solve_ivp(Pdot,
t_span=(0.0, tend),
y0=P0,
t_eval=teval,
method='RK45',
rtol=1e-6)
t = solution.t
P = solution.y
# Plots
if make_plots:
# Number Distribution
fig1, ax = plt.subplots()
fig1.suptitle("Number Distribution")
fig1.tight_layout()
s = np.arange(0, P0.size)
for i in range(0, t.size, round((t.size-1)/10)):
ax.plot(s, P[:, i], label=f"t={t[i]:.2g}")
ax.legend(loc="best")
ax.set_xlabel("Chain length")
ax.set_ylabel("Number of chains")
# Moments
orders = [0, 1, 2]
fig2, ax = plt.subplots(len(orders), sharex=True)
fig2.suptitle("Moments")
fig2.tight_layout()
fig2.align_ylabels()
for i, order in enumerate(orders):
m = moment(P, order)
ax[i].plot(t, m, label='numerical')
ax[i].set_ylabel(rf"$\lambda_{i}$")
ax[i].set_ylim(0.0, max(m)*1.05)
ax[-1].set_xlabel("Time")
return t, P
Ok, we’re ready for the final step. We just need to define an initial distribution and call solve_pbe().
# Initial distribution
imax = 100
i0 = 10
iwidth = 10
P0 = np.zeros(imax+1)
P0[i0+1:i0+1+iwidth] = 1.0
_ = solve_pbe(lambda t, P: propagation(P, M=1.0, k=1.0),
P0=P0,
tend=50.0)
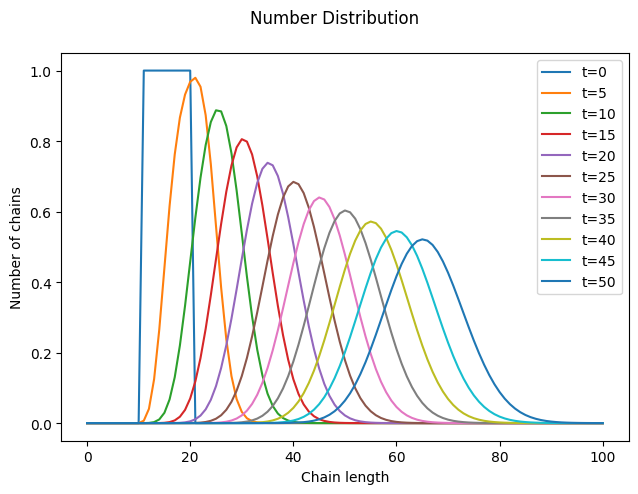
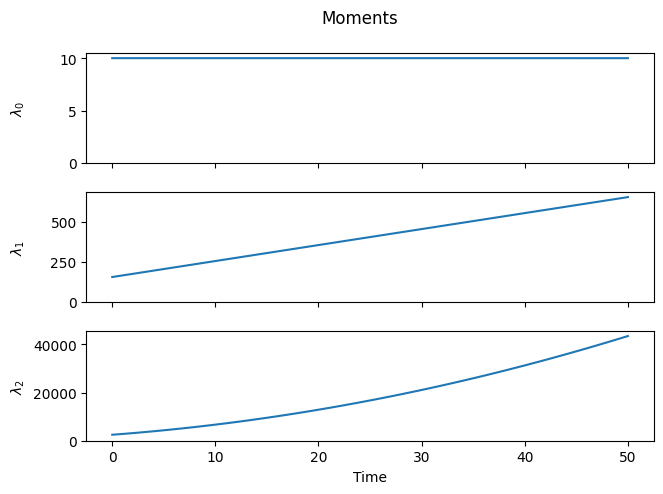
As expected, as time progresses, the distribution shifts to the right, the number of chains (\(\lambda_0\)) remains constant, and the higher-order moments increase.
However, a closer look at the distribution reveals something unexpected. We began with a “rectangular” distribution and assumed that all chains grow at the same rate, regardless of their length. Surprisingly, it turns out that some chains grew faster or slower than the average. Why is this?
This phenomenon is called Poisson broadening, and as the name suggests, it has a statistical origin. The monomer has no preference for any specific chain and will, on average, add the same number of times to each macromolecule. However, due to natural statistical variation, some chains will experience more or fewer addition events than the average.
1.1.2. 🔎 Questions#
What happens if we double
tend? Why?What happens if we simulate “backwards”, i.e. with a negative \(k\) or end time?
Derive an expression for the time derivative of the polydispersity index, \(PDI = \lambda_2 \lambda_0 / \lambda_1^2\).
1.2. Depropagation#
The chemical equation for the depropagation step is given by:
Here, \(k\) is the depropagation rate constant, and we assume it is independent of chain length. The corresponding population balance equation can be written as:
where \([P_i]\) represents the concentration of a polymer chain with \(i\) monomer units, and \([M]\) is the monomer concentration.
Next, the derivatives of the first three moments are:
These equations indicate:
The number of chains is conserved (since \(\dot{\lambda}_0 = 0\)).
The total number of monomer units incorporated into chains decreases at the same rate that the monomer concentration increases (i.e., \(\dot{\lambda}_1 = -\frac{\textrm{d}[M]}{\textrm{d}t}\)).
1.2.1. Numerical Solution#
Following what we did above for propagation, let’s define a function to evaluate \(\textrm{d}[P_i]/\textrm{d}t\) for the depropagation step.
def depropagation(P: np.ndarray, k: float) -> np.ndarray:
"""P(i) -> P(i-1) + M , k
d[P(i)]/dt = k*([P(i+1)] - [P(i)]), i>=2
d[P(1)]/dt = k*[P(2)]
"""
Pdot = k*(np.roll(P, -1) - P)
Pdot[-1] = -k*P[-1]
Pdot[1] = k*P[2]
Pdot[0] = 0.0
return Pdot
And now we solve it with a suitable initial distribution.
# Initial distribution
imax = 120
i0 = 100
iwidth = 10
P0 = np.zeros(imax+1)
P0[i0+1:i0+1+iwidth] = 1.0
_ = solve_pbe(lambda t, P: depropagation(P, k=1.0),
P0=P0,
tend=85.0)
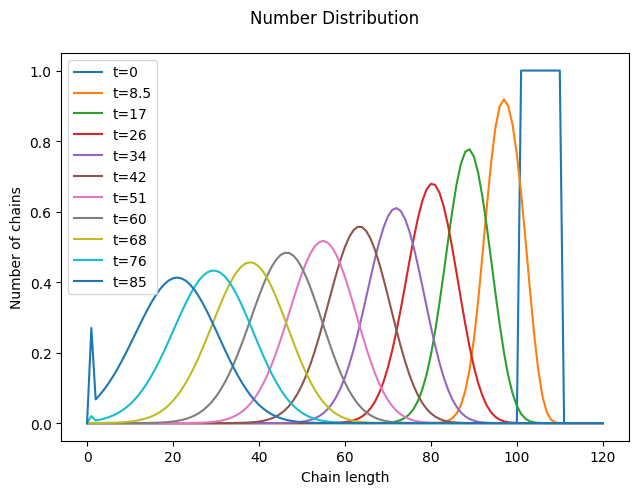
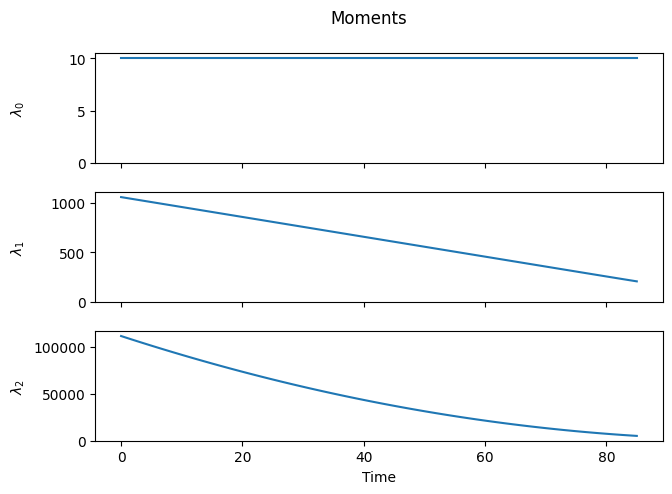
As expected, depropagation is almost like the reverse of propagation, with one subtle difference: chains cannot become smaller than a single monomer unit. As a result, at sufficiently long times, the distribution gets “smashed” against the \(i=1\) boundary.
1.2.2. 🔎 Questions#
Compare the population balance equations for propagation and depropagation. Why is depropagation not just the time reverse of propagation (ignore the factor \(k [M]\))?
What is the relationship between the difference equations for (de)propagation and the following hyperbolic partial differential equation?
\[ \frac{\partial P(i,t)}{\partial t} =- a\frac{\partial P(i,t)}{\partial i} + b\frac{\partial^2 P(i,t)}{\partial i^2} \]
1.3. Combination#
The chemical equation for the combination step is given by:
Here, \(k\) is the combination rate constant, and we assume it is independent of chain length. The corresponding population balance equation can be written as:
where \([P_i]\) represents the concentration of a polymer chain with \(i\) monomer units. The first summation on the right-hand side is a particular case of a discrete convolution.
Next, the derivatives of the first three moments are:
These equations indicate:
The number of chains decreases, since one chain is lost per combination event.
The total number of monomer units incorporated into chains remains constant, since mass is conserved during combination.
1.3.1. Numerical Solution#
Following the same approach as for the other reaction steps, let’s define a function to evaluate \(\textrm{d}[P_i]/\textrm{d}t\) for the combination step.
def combination(P: np.ndarray, k: float) -> np.ndarray:
"""P(i) + P(j) -> P(i+j) , k
d[P(i)]/dt = 0.5*k* sum j=1:i-1 [P(i-j)]*[P(j)] - k*[P(i)]*sum([P(j)])
"""
Pplus = 0.5 * np.convolve(P, P, mode='full')[:P.size]
Pminus = P*P.sum()
Pdot = k*(Pplus - Pminus)
return Pdot
Now, let’s solve it with a suitable initial distribution. Choosing a narrow initial distribution helps make the effects of combination more visible.
# Initial distribution
imax = 100
i0 = 8
iwidth = 3
P0 = np.zeros(imax+1)
P0[i0+1:i0+1+iwidth] = 1.0
_ = solve_pbe(lambda t, P: combination(P, k=1.0),
P0=P0,
tend=1.0)
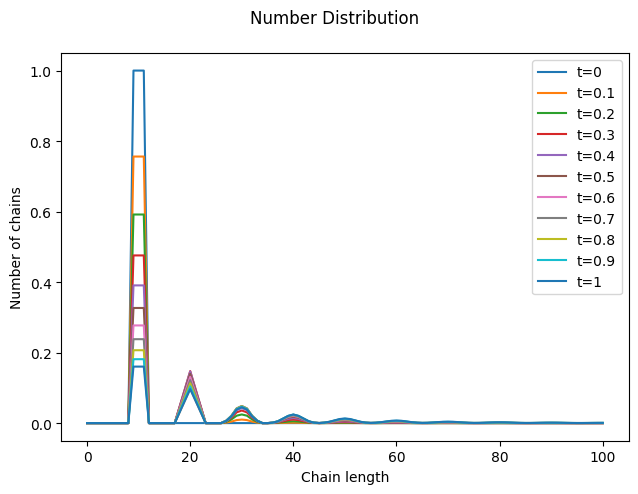
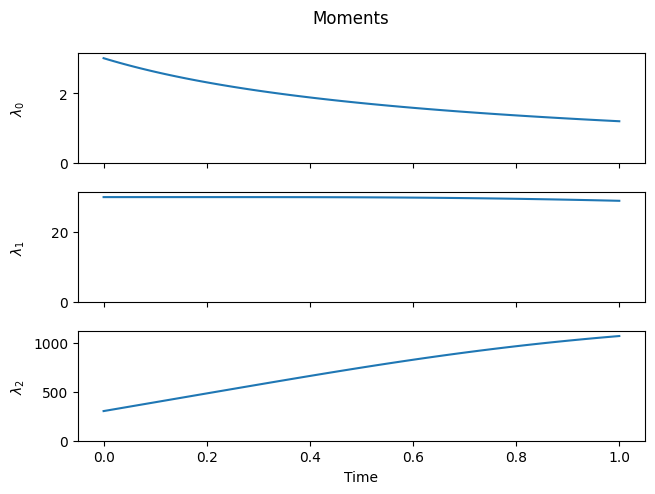
Notice how new chains are formed at integer multiples of the initial mean chain length. Also, observe the small loss of total mass (\(\lambda_1\)), which occurs because long chains are quickly formed and escape the numerical domain (you can fix it by increasing imax).
1.3.2. 🔎 Questions#
How would you describe the numerical complexity of the combination step compared to (de)propagation? Is it simpler or more complex? Why?
Name two types of concrete polymerization reactions that are particular forms of the combination step.
1.4. Random Scission#
The chemical equation for the random scission step is given by:
Here, \(k\) is the scission rate constant, and we assume it is independent of chain length. The corresponding population balance equation can be written as:
where \([P_i]\) represents the concentration of a polymer chain with \(i\) monomer units. The summation on the right-hand side is a particular case of a cumulative sum.
Next, the derivatives of the first three moments are:
These equations indicate:
The number of chains increases, since \(\lambda_1 \ge \lambda_0\) (the equality is only reached if/when all chains have unit length).
The total number of monomer units incorporated into chains remains constant, since mass is conserved during cleavage.
The moment equations do not form a closed set, since \(\lambda_2\) depends on \(\lambda_3\) and so forth.
1.4.1. Numerical Solution#
Following the same approach as for the other reaction steps, let’s define a function to evaluate \(\textrm{d}[P_i]/\textrm{d}t\) for the random scission step.
def scission(P: np.ndarray, k: float) -> np.ndarray:
"""P(i) -> P(i-j) + P(j) , k
d[P(i)]/dt = 2*k* sum j=i+1:∞ [P(j)] - k*(i-1)*[P(i)]
"""
# Source term
Pplus = np.zeros_like(P)
Pplus[1:-1] = 2* np.cumsum(P[2:][::-1])[::-1]
# Sink term
s = np.arange(0, P.size)
Pminus = (s - 1)*P
Pminus[0] = 0.0
Pdot = k*(Pplus - Pminus)
return Pdot
Now, let’s solve it using a suitable initial distribution, such as the one we used for the depropagation step.
# Initial distribution
imax = 120
i0 = 100
iwidth = 10
P0 = np.zeros(imax+1)
P0[i0+1:i0+1+iwidth] = 1.0
_ = solve_pbe(lambda t, P: scission(P, k=1.0),
P0=P0,
tend=0.02)
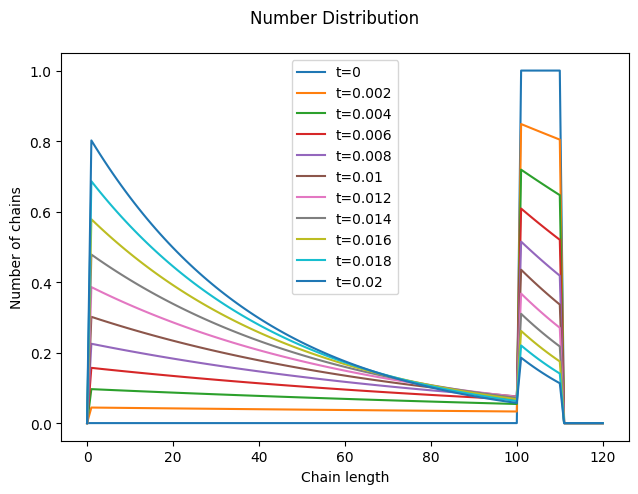
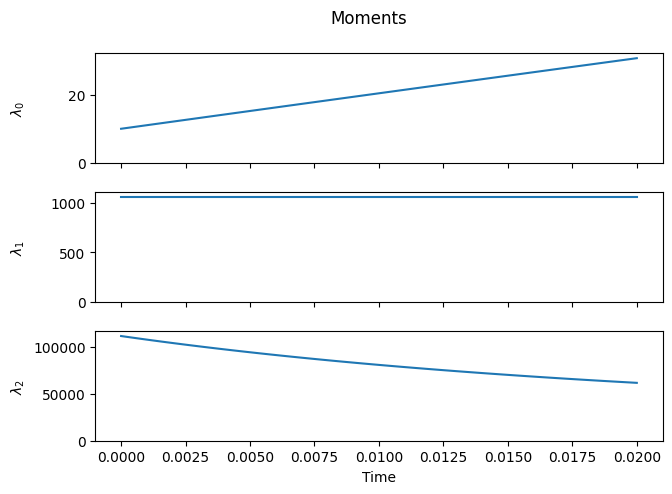
Since scission is assumed to occur randomly along the chain, the distribution of the new chains is initially uniform (the portion of the orange curve between 0 and 100 is flat). As scission progresses, the relative fraction of shorter chains increases, and the distribution increasingly resembles a (truncated) geometric distribution.
1.5. ✨ Plot Animation#
Animating plots is both easy and fun with matplotlib!
For this example, we will use the PillowWriter to create an animated plot for the depropagation step, based on the conditions outlined in the respective section.
from matplotlib.animation import PillowWriter
We first compute the solution over time, just as we did earlier.
# Initial distribution
imax = 120
i0 = 100
iwidth = 10
P0 = np.zeros(imax+1)
P0[i0+1:i0+1+iwidth] = 1.0
t, P = solve_pbe(lambda t, P: depropagation(P, k=1.0),
P0=P0,
tend=85.0,
make_plots=False)
Then, we set up the canvas (which remains constant throughout the animation) and update the distribution for each time step. Voilà!
# define canvas
fig, ax = plt.subplots()
ax.set_xlabel("Chain length")
ax.set_ylabel("Number of chains")
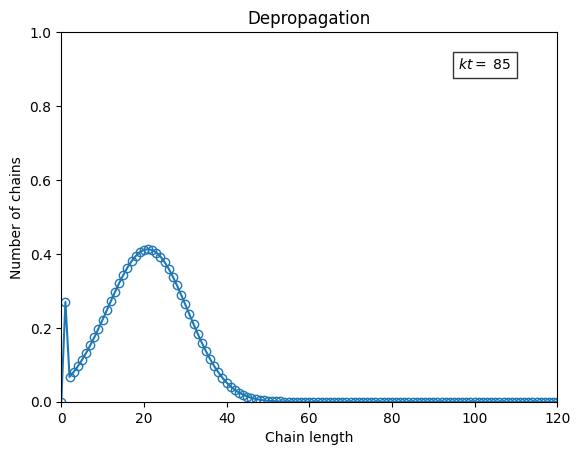
ax.set_title("Depropagation")
s = np.arange(0, P0.size)
ax.set_xlim(*s[(0, -1),])
ax.set_ylim(0.0, P.max())
line, = ax.plot([], [], '-o', fillstyle='none')
text = ax.text(0.8*s[-1], 0.9*P.max(), "", bbox=dict(facecolor='white', alpha=0.8))
# animation
fps = 20
writer = PillowWriter(fps=fps)
with writer.saving(fig, "animation_depropagation.gif", 150):
for i, ti in enumerate(t):
line.set_data(s, P[:, i])
text.set_text(rf"$kt=$ {ti:.2g}")
writer.grab_frame()
if i == len(t):
for ii in range(2*fps):
writer.grab_frame()